Got out of bed and ... it has crashed again. Ran for 5hrs. So it isn't simply that printf. Same trace data as before.
I put a breakpoint on the _malloc_r and found it gets called right away, in this
ck_1 = HAL_RCC_GetPCLK1Freq();
ck_2 = HAL_RCC_GetPCLK2Freq();
printf("PCLK1=%ld PCLK2=%ld\n",ck_1,ck_2);
which is nothing to do with %f. That btw uses a printf which has had its out redirected to the SWD console so you can do debugs to the debugger window at high speed. It does sort of work... but I will remove it now
There is a mutex passed through, fwiw.
So this printf uses malloc for just about everything! But whose heap?
Anyway, not sure what I can do about that. Obviously it is not thread safe. I probably need to mutex printf sprintf but then mutexes are not accessible until osKernelInitialize().
I did a fixed _sbrk for the general heap malloc but if this _malloc_r is getting a wrong value, that will be broken. Where is it placing the heap? The source - thanks cv007 - says
107 Supporting OS subroutines required: <<close>>, <<fstat>>, <<isatty>>,
108 <<lseek>>, <<read>>, <<sbrk>>, <<write>>.
I fixed sbrk (and I see _sbrk is at the same address) a long time ago. But that source does not reference sbrk so where does this printf place its heap? The initial call to _malloc_r has this register content
General Registers General Purpose and FPU Register Group
r0 0x20000598 (Hex)
r1 0x400 (Hex)
r2 0x1 (Hex)
r3 0x400 (Hex)
r4 0x200008ec (Hex)
r5 0x800 (Hex)
r6 0x20000598 (Hex)
r7 0x2001fd90 (Hex)
r8 0x80086cc (Hex)
r9 0x200008ec (Hex)
r10 0x20000598 (Hex)
r11 0x0 (Hex)
r12 0x0 (Hex)
sp 0x2001fb38 (Hex)
lr 0x8048407 (Hex)
pc 0x8042728 (Hex)
xpsr 0x1000000 (Hex)
d0 0x0 (Hex)
d1 0x0 (Hex)
d2 0x0 (Hex)
d3 0x0 (Hex)
d4 0x0 (Hex)
and while I don't know which registers are used for the parameters, I would bet it is allocating 0x400 (R1) or 0x800 (R5) which is 1k or 2k!
It calls _sbrk_r
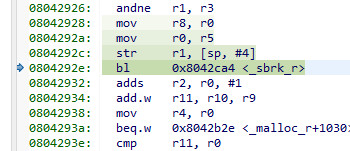
and the source for that is
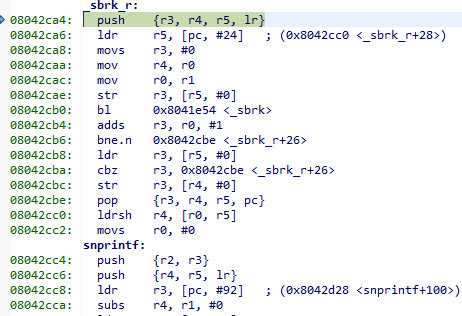
which calls _sbrk. Funny how arm implements a RET... they pop the PC

The funny thing is that this heap seems to get discarded when printf returns. Or does it? Does the first call to "printf" grab a block? It would need to use some global variables which get preserved. Normally you don't need to call sbrk to do a malloc, but you do need to call it when creating a new heap, on an existing heap.
Then it gets more complicated. I am tracing calls to sbrk, to see where this "printf heap" is going, and I find calls to the normal malloc is calling _malloc_r !!!! So we come full circle
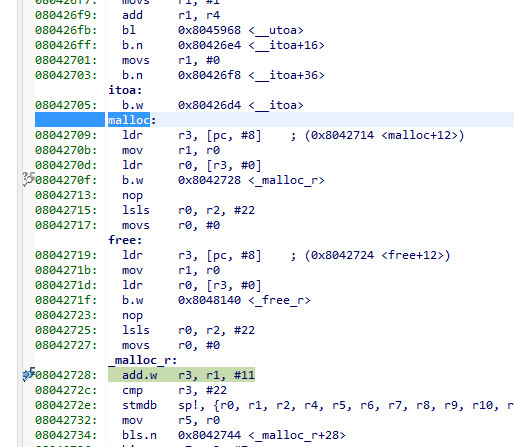
and I see no calls to _free_r (well not until TLS is running and I know about that one; it gets a 48k block which is freed when the https session ends, about once a minute).
Clearly the printf family is using the general heap for every call. And it never calls free(). That means it must be storing a pointer to its block somewhere. But it still does a malloc call on every subsequent use.
A key question is whether this heap is really mutex protected. It looks like it is. Does anyone recognise this
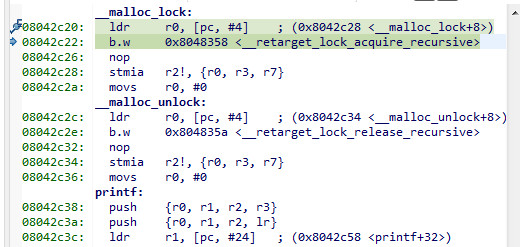
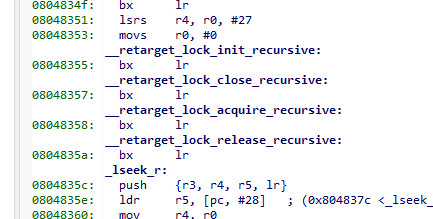
A google on __retarget_lock_acquire_recursive shows that this is indeed an empty function, and this
https://gist.github.com/thomask77/65591d78070ace68885d3fd05cdebe3adescribes the right code for that - using one of the FreeRTOS mutexes.
So this newlib printf has not been correctly implemented on this system.
This
https://www.freertos.org/FreeRTOS_Support_Forum_Archive/May_2017/freertos_printf_and_heap_4_f2b0ee0cj.htmlsuggests there is a solution, with FreeRTOS having a proper printf printf-stdarg.c. This is referenced in comments in the FR files but it says it is an incomplete version (no float output for example).
I think I need a new printf which does not use the heap except for %f.
I still don't know if this is the cause of the crashing but it is a good candidate.
I unchecked the newlib-nano checkboxes and it still calls malloc for the integer output, and it calls those empty mutexes...
But I found something
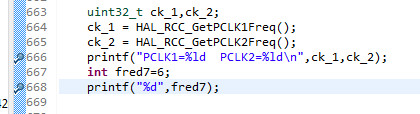
The 1st printf calls malloc but the 2nd one doesn't. Same for calling __retarget_lock_init_recursive. So maybe the heap (and its attempted protection) is used for %f and for longs only.
How can one make those empty mutex functions call proper ones, given that a) I don't have the C source and b) they are presumably not defined as weak?




